Why you need MLOps to build agile ML products
Most Machine Learning (ML) models never reach production. They stay in notebook experimentation heaven where everything is about data science. A proof of concept ML model in a notebook is one thing. Going from a notebook to production is a whole other ball game. It requires the entire end-to-end data and ML pipeline to be resilient, cloud efficient, and accessible to end-users and maintainers as a reproducible software product. This is what MLOps is all about.
In this post, we try to briefly explain what MLOps is and why it fits so nicely together with agile product development.
Prototype or product?
Would you rather have
- a custom built ML model with advanced feature engineering and a great performance score in a local notebook inaccessible to end-users and based on offline data, or
- a globally available robust data pipeline producing high quality and timely relevant results, applying a deployed model that barely beats your baseline model, but is used by end-users?
Option 1 sounds more Kaggle-like and challenging from a Data Scientist perspective. Whereas option 2 actually made it all the way to production as a value-creating prototype.
For a Data Scientist the task of building a useful model is not always hard. Putting it in production is. However, it is only in production that ML delivers value as a product.
Focus on the product from the beginning. Work on the full pipeline even when experimenting. As more and more high quality tools for automating model choosing and training emerge, we should focus our attention on end-to-end pipeline building and quickly exploring the unknowns all the way from data input to output visualization. Having a small but functioning prototype pipeline follows agile principles and a minimalist path to building ML products.
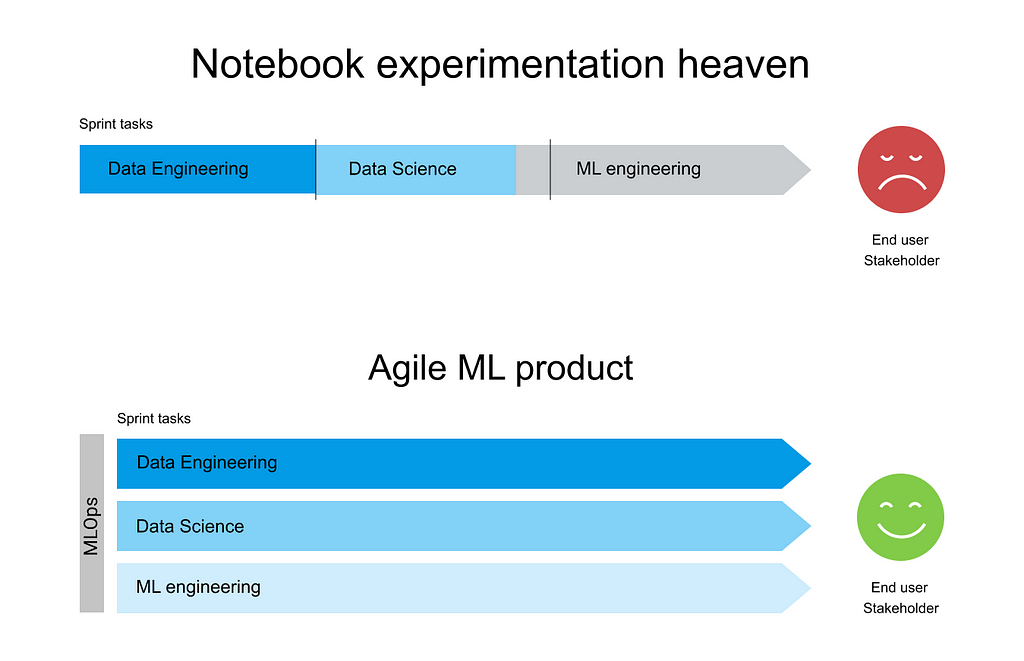
If your ML project goal is mostly research oriented and it is to demonstrate that a data set and a model can solve a given problem, then worrying about automating the operational part and deploying the model to be available for end-users might seem far away. Maybe you don’t even have end-users ready to test your solution.
However, as long as you don’t have anything deployed and accessible to end-users through reproducible training procedures and pipelines, you don’t have a working product solving your business problems. Furthermore, you are breaking agile principles by valuing experimentation and model improvement higher than delivering a working agile prototype to end-users. Improving the ML model performance by another percent often requires significant effort and should not be a priority if the pipeline for deploying the ML model is not operational.
Building your ML product in an agile fashion requires an end-to-end pipeline mindset from the beginning. That is the mindset of MLOps.
MLOps = data + model + code
In contrast with traditional software an ML model is not just code. An ML model is a function of a specific data set and training procedure. Once trained, an ML model is basically a rule set to provide answers from new unseen data.
- Traditional software implements the rule set directly through code.
- ML code first implements the procedure to generate the rule set.
- MLOps code implements the procedure to generate the ML code.
Including all the other glue and stuff that usually takes up most effort when building a product around an ML model, ML code is normally a small piece of the entire code base. It’s not all the operational stuff that actually releases and maintains your ML model experiment as a reproducible software product.
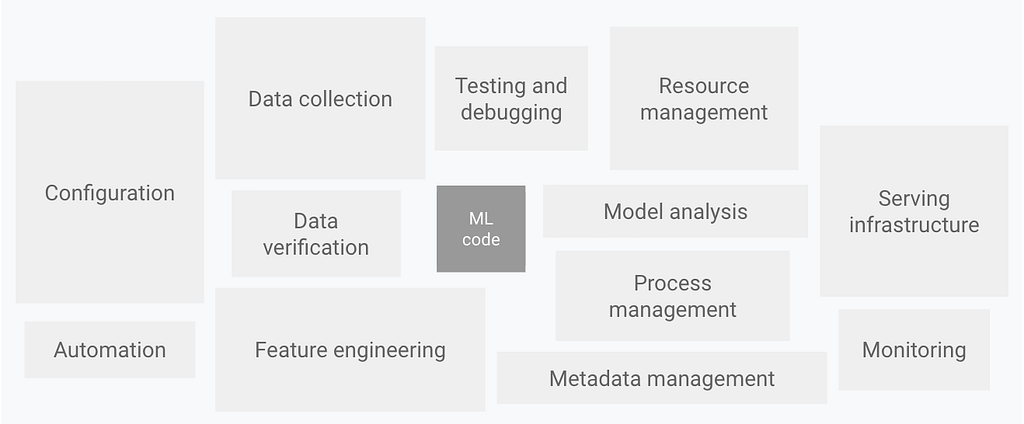
“MLOps is a methodology for ML engineering that unifies ML system development (the ML part) with ML system operations (the Ops part). It advocates formalizing and when beneficial automating critical steps of ML system construction. MLOps provides a set of standardized processes and technology capabilities for building, deploying, and operationalizing ML systems rapidly and reliably.” (Google’s MLOps definition)
MLOps manages the life cycle of data, models and code. The combination of maintaining these three is a big challenge. It involves managing the complex multi-step ML workflow in a pipeline and ensuring that each step runs in a reproducible, cost-effective and scalable way. MLOps is a great practice to deliver high quality working software frequently and as fast as possible.
Agile ML products
If we really strive to follow agile principles when building ML products, a priority is to fully automate a pipeline for exposing our ML model to end-users as quickly as possible. Then iterate.
Often the biggest value for end-users is simply to get a steady supply of clean and visualized data. So start there. With no model.
Then add a simple model and deploy as part of the full pipeline. Iterate from there and keep comparing your scores to a baseline model. Simple models are often hard to beat and contribute to the biggest performance gains.
Setting up the end-to-end pipeline early on also ensures that the most basic data is available and robust enough for production. Finally, the ability to explore the unknowns must be an integrated part all the way down to end-users right from the beginning.
Avoid getting stuck in the endless model building loop in notebook experimentation heaven. You can always improve the model! People spend months on Kaggle squeezing out an extra 0.1% in the performance metrics. Even the experimentation phase requires automation and versioning but is unfortunately often omitted.
Build your library of reusable MLOps components to ease maintenance and accelerate your next ML pipeline prototype and experiments.
We need best practice reusable blueprints to go from a hacky ML experiment to a professional agile ML product. Building the entire pipeline requires a wide range of skills with specifics that change all the time. If you don’t know how. Please ask.
Why you need MLOps to build agile ML products was originally published in Grensesnittet on Medium, where people are continuing the conversation by highlighting and responding to this story.