Secure chat on own live data (part 1)
Challenge
Chatting or searching with the help of generative AI on your own data is popular.
The solutions are typically Retrieval Augmented Generation (RAG) Apps⁹ in some form. How to secure these, both with respect to app and data access, confidentiality and inappropriate response content is often a challenge. How to secure these on live data, i.e. things that may have changed just now, is an additional challenge. This series of articles reviews common solutions and offers practical ways to plug the holes.
Consider the common need to chat or search across multiple private data sources.
“How do we make sure the chat is only on data the user has access to?”.
“Does the data access reflect recent changes to access policy?”
“Does the chat reflect recent changes to source content?”
Some clients come with such concerns. Or requirements if you will. At Computas, an independent consultancy, we provide tailored solutions, that being custom code or products with configuration. What do we suggest for clients that have the type of concerns exemplified above?
Let’s assume for this article that the requirements are
- The generative AI based queries (e.g. search or chat) is to span data sources from several vendors and/or products. Let’s call this requirement “Sources”.
- When a query is submitted, the solution shall only take into account data the specific logged-in user doing the query has access to. We name this data source “Access control”.
- If there is a change in access, the response to a query, must take this into account immediately. We name this “Access Freshness”.
- If there is a change in the content of a data source, response to a query, must take this into account immediately. We name this “Data Freshness”.
The title speaks of “secure”. In this part and part 2 we deal with how to secure access to and confidentiality of the data sources. There is a lot more to securing RAG solutions⁸. We dive into that in part 3. See the bottom of the article to get to the latter parts.
Alternatives
When considering chat or search on own data, many clients reach for one of the many generative AI chat/search-as-a-service products out there, and by extension do not deal directly with the intricacies of a RAG. It is hard however to find mature products that cater to the above requirements.
Let’s look at some common alternatives.
Consider a primary data source product which provides its own LLM based chat/search/summarization solution. Atlassian Intelligence for Confluence¹ for example. You get access to data constrained by what the logged in user has access to. When access permissions change to a document, the search is reindexed with low, but not necessarily immediate latency². You do not get a service that spans data sources from different vendors or sources. So in terms of requirements the alternative supports a single source, supports access control at user level, access freshness and content freshness is near immediate.
You do however get multiple data sources and security with an enterprise search provider. Consider Elastic’s generative AI offering, the Relevance Engine³. You have built in access control tailored to the specific user doing the query. The access reflects the state of affairs at the last import and index however. So if there has been changes since then at the source, that is not reflected in the search. And there are non-trivial issues with mapping the semantics of the access constraints at the source with the access control model in the search engine. Summing up, this alternative supports multiple data sources, access control at user level and both access constraints and content refreshes when new content is imported and reindexed. For the purposes of this article we categorize that as cached access and content freshness.
What about open cloud AI platform products?
For example, you might reach for Google Vertex AI Agent Builder. This is a platform where you quickly create a chat or search solution. Via connectors (“data stores” in their parlance) you provide data for an LLM enabling the chat. You can create your own connector, where you connect to a 3rd party data source, upload the data to a store within the confines of the Agent Builder product. There is control of access to the data, but at upload time, i.e. prior to indexing of the data⁴. If there is change to access permissions at the source it will not be reflected before a new import is performed. And there are possibilities of configuration mismatches between access constraint definitions at import time and constraint enforcement at the time of query. Additionally, if the data at the source changes, that is not reflected before new data has been imported to the data store. Summing up, this alternative supports multiple data sources, data source access control is in general at the level of logging in by a system user and access and content freshness we categorize as cached.
Let’s reach for Azure AI studio instead. The setup is very similar to the one above. In general you connect to a data source. You import data. The studio indexes the source data and makes it available to an LLM enabling the chat. You get slightly better support for authentication to third party data sources, but it remains a challenge that access to data is checked and is retrieved at construction time, and it is disjoint from the access privileges that the logged in user consuming the services might have. In general we summarize the alternative as we did with the Google alternative.
Finally, you might consider an end-to-end suite that caters for both multiple sources, user interface and everything in between. E.g. Microsoft 365 copilot. It does chat and search. It does multiple data sources. It makes sure that it only uses data that you as a logged-in user have access to⁵ ⁶. So, that’s it you might say. Not so fast. Also here, changes to the data at source might not be reflected if there is a while since last time the underlying Microsoft Graph imported data⁷. And changes to user access since the last import will not be reflected either. And then there is the broader issue of whether Microsoft 365 Copilot and the Graph product is a good fit for the client’s use case. It is, as it is with many other solutions, a considerable vendor lock-in. Many design decisions have been made for you, both in terms of data model, sharing and user interface. Summing up, the alternative supports multiple data sources, data source access control is at a user level and access and content freshness we categorize as cached.
We sum up our informal alternative categorization;
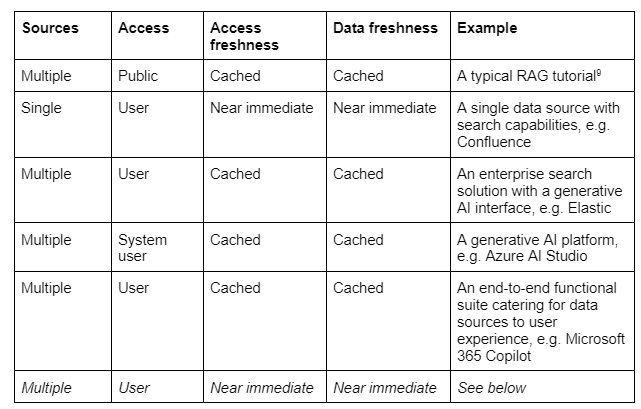
Now, as you see, the alternatives could all do better at some or several requirements. Could we devise an approach which spans multiple data sources, enforces data source access constraints at the level of the logged in user doing the query and ensures that both access and content freshness is near immediate?
Yes there is. We’ll cover that in part 2 and part 3. Get access here.
References
[1] “Supercharge your workflows with Atlassian AI”, https://www.atlassian.com/software/confluence/resources/guides/best-practices/atlassian-ai
[2] “Page Restrictions Performance Considerations”, “https://confluence.atlassian.com/confkb/page-restrictions-performance-considerations-200705378.html
[3] “What is Elasticsearch Relevance Engine (ESRE)?”, https://www.elastic.co/guide/en/esre/current/learn.html
[4] “Use data source access control”, https://cloud.google.com/generative-ai-app-builder/docs/data-source-access-control
[5] “Microsoft Graph connectors overview” https://learn.microsoft.com/en-us/graph/connecting-external-content-connectors-overview
[6] “Microsoft Graph connectors SDK connector OAuth API”, https://learn.microsoft.com/en-us/graph/custom-connector-sdk-contracts-connectoroauth
[7] “Set up Microsoft Graph connectors in the Microsoft 365 admin center”, https://learn.microsoft.com/en-us/microsoftsearch/configure-connector
[8] “Mitigating Security Risks in Retrieval Augmented Generation (RAG) LLM Applications”, https://cloudsecurityalliance.org/blog/2023/11/22/mitigating-security-risks-in-retrieval-augmented-generation-rag-llm-applications
[9] “Build a Retrieval Augmented Generation (RAG) App”, https://python.langchain.com/v0.2/docs/tutorials/rag/
Secure chat on own live data (part 1) was originally published in Compendium on Medium, where people are continuing the conversation by highlighting and responding to this story.