Simplifying parallell processing in .NET

I’m currently on a project for a company responsible for supplying district heating to the capital of Norway, Oslo. As a part of this, we receive IoT sensor data at a daily basis. One of our applications is responsible for reading measurements from Azure EventHub, processing the measurements, before writing the result to Google Bigtable and Google Pub/Sub. The application is running in a Kubernetes cluster, and is able to horizontally scale up and down based on CPU usage. The problem is that if the application is doing a lot of IO operations, the CPU usage might be minimal, making it challenging to set auto-scaling based on CPU load. And in order to speed up processing of measurements, we might have to scale up to 10–20 instances, because of poor utilization of the resources available. This increase will most likely incur a higher cost, as each running container also adds some resource overhead. This is why we as developers need to be good at writing applications that utilize the CPU, memory and IO available optimally. Not just to reduce costs, but also to reduce the time needed to complete a job, minimizing latency through the system, resulting in responsive experience for the users.
In this post, we will go through the use of several techniques for getting the most out of your .NET workloads.
Picture an application responsible for reading messages from a queue, doing some kind of processing before writing the result to a database.

Single-threaded
If this application was written as a single threaded loop, the basic loop of the application would look something like the example below.
https://medium.com/media/9c484dc89402fe776e124f4f0cc922b5/href
This application will do the job, but will most probably not utilize the most the CPU, as there are a lot of IO operations happening. A single instance like this would struggle to achieve high throughput. Running multiple instances would be the only option to increase throughput.
By translating this in to a simplified graph, it is possible to see that input, CPU and output is only utilized one at a time. If reading, processing and writing takes the same amount of time each, an application like this would only utilize about a third of the available resources.
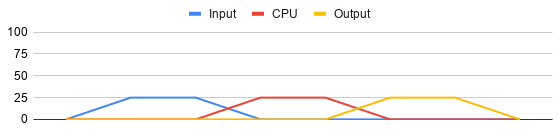
Multiple Tasks
It’s possible to run multiple tasks internally in the application to increase throughput, just by instantiating multiple instances of the task from the single-threaded example.
https://medium.com/media/7b1953201eface90e5254008954e5d71/href
This will probably increase throughput, but not necessarily. We might get lucky, and have the input, CPU and output load evenly distributed.

But most likely, the messages will not be flowing in like a steady stream. In that case, we’ll end up with several of the threads reading, processing and writing at the same time. This causes peak loads, and still a lot of non-utilized resources.
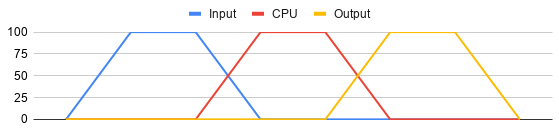
Running multiple tasks also introduces a whole set of new challenges, because now we have to make sure everything is thread-safe. This will typically include different locking methods for accessing shared collections and dependencies, which increases complexity, and usually affects overall performance.
Threading.Channel
The next option is a fairly new one, and was introduced late 2019. It allows for a thread-safe method for internal queuing in .NET. It requires us to rethink our simple example though, and split it into three different phases using Threading.Channel for handover between threads.
https://medium.com/media/fb1cb3b66265f2c74cf30851e6d9d300/href
The application is now rewritten to allow for separation of concern. This allows the reading, processing and writing tasks to work as fast as they’re able to, with one task each. This gives us a little more wiggle room for optimization, but also several pitfalls to look out for. Allowing the tasks to run at their own full speed is both good, and probably a problem, as the processing task is most likely the bottleneck here. Let’s start by adding more tasks for the processing step in the pipeline.
https://medium.com/media/5a89a343ce198d8674f4c1225b993826/href
We now have four tasks running the processing step. This also assumes that ProcessMessageAsync on line 27 is thread-safe. But the other two parts of the pipeline, ReadMessagesAsync on line 10, and WriteResultAsync on line 40, do not have to be thread-safe. It is worth pointing out that Threading.Channel will only help with the transfer of “ownership” of an object between threads, but it does this one task really well, allowing us to design our code around this.
But, what if four processing tasks are not enough, and the application keeps reading messages from the input queue much faster than the application can process them. This will end up with the application memory filling up as the channels store more and more messages. This is because we used Channel.CreateUnbounded<T> instead of Channel.CreateBounded<T>. Usage of the latter would limit the available space in the channels, setting a maximum number of messages available in the channel.
https://medium.com/media/6bbe5d0e10d6578a89f9d4c756c73ffd/href
We have now introduced the concept of back pressure, forcing the reading task to wait when there is no more room for messages.
By splitting the code into three parts, we also introduced a new issue when writing the results to the database. More specifically, we now write a single result at a time, which results in a lot of requests to the database. To optimize writing to the database, we have to batch the results in batches of e.g. 200 results at a time.
https://medium.com/media/505bfdfb0834da3d455a9738850871a3/href
What used to be a simple application, is now far more complex. But in return, the application is now much more able to utilize the available CPU and IO.
A last issue that we have not addressed with using Treading.Channel for multi-threading, is flushing the pipeline. If we request the application to shut down by calling Cancel() on the cancellation token, all the pipeline tasks will just stop what they are doing without emptying the channels. This of course could also be handled, but we have to implement the logic ourselves.
Task Parallell Library
Over to the last solution we will present: TPL (Task Parallell Library.) This library has been around for years now, and has been my go-to library for simplifying multi-threading. TPL can be considered as a superset of Threading.Channel, that adds a lot of functionality for pipeline processing. Note that a basic Channel is much faster than TPL for basic stuff, like handing over objects from one thread to another. But you have to implement and maintain a lot of logic yourself that you get for free from TPL.
https://medium.com/media/0406c36c432c697d7402cdf29cdc5ed7/href
Let’s go through what is happening here. First we create a TransformBlock block to handle processing messages, by transforming the input from a Message to a Result. The BoundedCapacity is set to 1000, to enforce back pressure on the reader. The MaxDegreeOfParallelism is set to 4, to allow it to use up to four parallel tasks. After this a BatchBlock is used to create batches of 200 results, before handing over each batch to the final ActionBlock, writing the result to the database.
By linking the blocks together, we achieve a pipeline with back pressure out of the box. By setting the linked blocks to PropagateCompletion, we can inform the entry block of the pipeline that no more messages will be offered. This will result in the pipeline being shut down as the last message flows through each block, effectively flushing the pipeline for cached messages and results.
By using TPL, we were able to achieve much simpler code, without having to implement everything ourselves. Task Parallel Library is by far an underrated, and to many, an unknown library which can simplify writing performant applications.
Note that even though we have focused on best utilizing the CPU usage of each application instance, this could just as easily be written to multi-thread reading from the input queue, or writing to the database. What suits you best depends on what’s the bottleneck in your system.
If your application is IO bound, meaning that your application is limited by IO to a subsystem, there’s not that much you can do if you’re constantly hitting that IO limit. If your application is not constantly hitting that IO limit, either the Threading.Channel or TPL approach might help you squeeze out that last bit of performance.
If your application is not IO bound, and you’re using a distributed database like Google Bigtable or Azure CosmosDb, you are still limited to x CPUs per instance. Even though Threading.Channel and TPL will help you distribute load evenly, they are still more complex to use than just firing up several more tasks in order to utilize more of the CPU.
- If your application doesn’t need to transfer objects between threads, and mostly does CPU intensive work, multiple tasks might be the easiest choice.
- If your application has some need for handing over objects between threads, but doesn’t care about loosing messages when channels are not flushed, Threading.Channel might be the option for you.
- But if your application consists of long pipelines with a lot of steps, or needs to control flushing of the pipeline, you should consider using Task Parallel Library.
Simplifying parallell processing in .NET was originally published in Grensesnittet on Medium, where people are continuing the conversation by highlighting and responding to this story.