How fast is generative cloud AI?
The tech titans provide a variety of large language models. Clients try to balance quality, cost and latency. You generally want fast response, top response quality and minimal cost.
Many applications suffer from long response times. Which model do you choose to get better response times? If your choice of model improves response times how does the quality fare? And do you save money?
In this short article we focus on response times. We look at Google Gemini⁷ and OpenAI GPT⁸ non-streaming chat completion calls and measure what seems to influence latency.

What do the vendors promise?
OpenAI doesn’t guarantee anything w.r.t. response times³. Azure’s OpenAI services and Google provides uptime guarantees for OpenAI/Gemini respectively, but no guarantees on the maximum response time for an individual call to the api⁴ ⁵ ⁶.
Microsoft does however provide a fairly good advisory on what might influence latency¹. Here we learn
- Model type, prompt length and response length are what matters
- Response length trumps prompt length particularly when the lengths are large.
Empirical findings
So how does this play out in practice?
Let’s find out. For each model, Gemini and GPT variants, I timestamp the same chat completion query⁹ . Since the advisory indicates response length is an important parameter, I ask the model to reply with lengths 10, 100 and 1000 words. The actual response lengths in bytes will vary considerably, albeit within a certain band.
I’ve plotted some results below. The latency is in ms. Length is in bytes. The query/prompt itself is about 100 bytes.
Does response length matter?
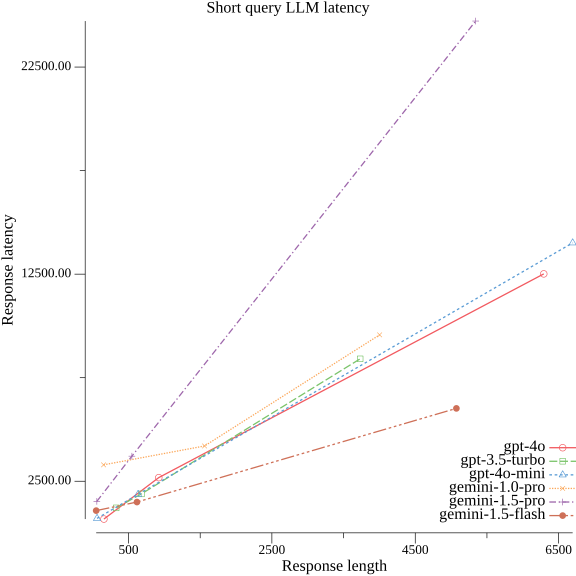
I observe:
- Broadly speaking response length correlates with response latency. That fits well with the advisory from Microsoft.
- Response latency is considerable, particularly for the more advanced models. Some take more than 10 seconds routinely.
- For some models the response length matters a lot. For gemini-1.5-pro it matters most, whereas for gemini-1.5-flash it matters least.
Does query length matter?
The advisory states that the prompt length also matters, albeit much less than response length. Let’s investigate that as well.
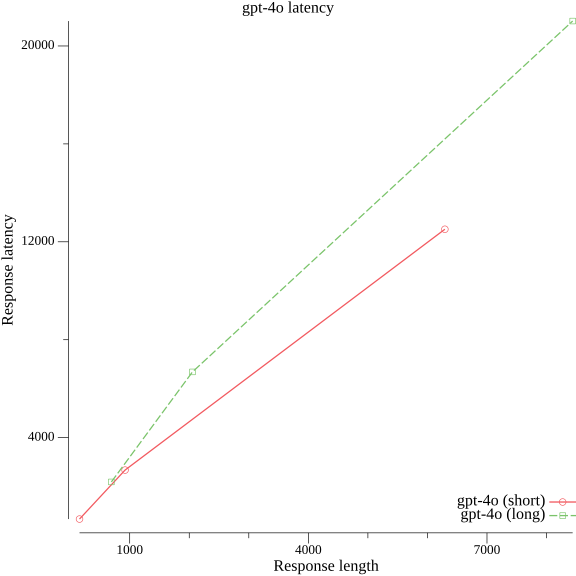
Looking at Gpt-4o below, the red line is the same as from previous figure, being the same query of about 100 bytes . Comparing that with a query with length of about 25 kilobytes, the green dotted line shows us that for short responses the latency is comparable, whereas for long queries, the latency is worse by a double digit percentage if the query is long.
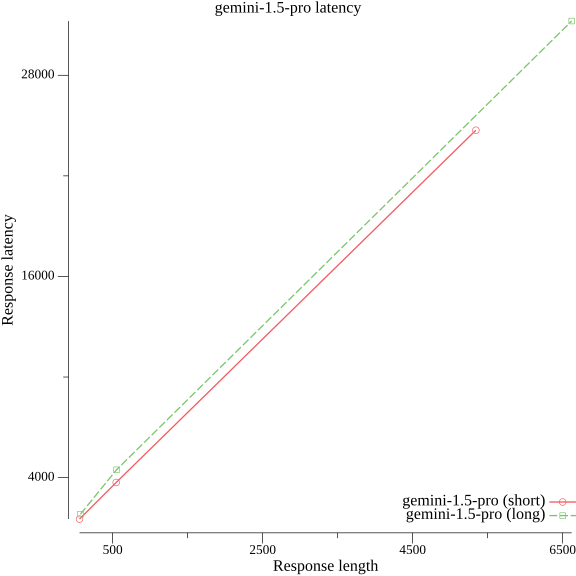
Not all models are like this however. For the Gemini-1.5-pro query length doesn’t seem to matter much.
Large language models are stochastic in nature. The results above are only a single sample. See the gitlab repository⁹ for graphs of all the models and run the Go code yourself to see if your results compare with mine.
Summary
What did we find out?
Response length matters. The longer the response, the longer the the time it takes to get an answer. For the largest and newest models from both vendors this is most pronounced.
Query (or prompt) length does not matter much. Ask a question of a 100 bytes or 25 kilobytes, the answer comes back at roughly the same speed.
The response times in absolute numbers are strikingly large. For a response length of about 7000 bytes, Gpt-4o will come back to you in 20+ seconds, and with Gemini-1.5-pro you might wait half a minute.
References
[1] “Performance and latency”, https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/latency
[2] “Making GPT API responses faster”, https://www.taivo.ai/__making-gpt-api-responses-faster/
[3] “Is there an SLA for latency guarantees on the various engines?”, https://help.openai.com/en/articles/5008641-is-there-an-sla-for-latency-guarantees-on-the-various-engines
[4] “Gemini for Google Cloud Service Level Agreement (SLA)”, https://cloud.google.com/products/gemini/sla?hl=en
[5] “Gemini Online Inference on Vertex AI Service Level Agreement (SLA)”, https://cloud.google.com/vertex-ai/generative-ai/sla?hl=en
[6] “Service Level Agreements (SLA) for Online Services”, https://www.microsoft.com/licensing/docs/view/Service-Level-Agreements-SLA-for-Online-Services?lang=1
[7] “Innovate faster with enterprise-ready AI, enhanced by Gemini models”, https://cloud.google.com/vertex-ai
[8] “The most powerful platform for building AI products”, https://openai.com/api/
[9] https://gitlab.com/yarc68000/llm_benchmark
How fast is generative cloud AI? was originally published in Compendium on Medium, where people are continuing the conversation by highlighting and responding to this story.