Building a serverless datawarehouse pipeline using GCP
Traditionally, building a data warehouse requires massive capital investments in infrastructure, tools and licenses to get insight to your data. As they live and grow, these solutions often have a tendency to become time-consuming to maintain and complex or slow to change in response to new business needs.
BigQuery is a serverless datawarehouse solution provided by the Google Cloud Platform. A datawarehouse is nothing without data, which is typically provided from a pipeline connected to your data sources.
In this blog post I will only focus on the serverless integration offers that GCP provides. This means that popular components like Cloud Composer and Data Fusion are not part of the solution, even though they fit in with the overall architecture.
In serverless you do not have to worry about the infrastructure that runs the services, it is all managed by the platform.
An attractive part of this is that the operational expendure starts at $0, and you only pay for what you use (usually with a generous free tier). If you have a significant size, serverless integration might not be the most cost effective, and other options should also be explored.
Feel free to reach out if you need an expert opinion!
Data Sources and Integration

Data sources and integrations is a topic that speaks variation. Sources can have api based access or direct access to databases, and all the alternatives in between. Sometimes the system you integrate with has clearly defined service contracts (what kind of data it has), while some systems (especially legacy or custom made) does not facilitate this and you have to spend time discovering the system internals.
Ingestion of data sources is typically done in batch or streaming.
A good pattern to ingest batch data to GCP would be to call a program that reads from the source at regular intervals and store this to cloud storage in a format that can be loaded into BigQuery. A daily batch job could, for example, write objects in this format: SOURCE_SYSTEM/batch/YEAR/MONTH/DAY.json
If you have streaming data then it’s a good pattern to put messages on a queue. This allows for easy service upgrade on your end while not losing data when the integration layer is upgraded. A queue also acts as a multiplex, allowing you to process the same data using different pipelines. Depending on the stream frequency and payload, also consider storing the objects in cloud storage for easy reprocessing if needed. It has certainly helped me on several occasions just recreating a BQ table from cloud storage, instead of dealing with a slow 3rd party source.
Given that you have your data sources in place and you have chosen your integration components, you need to address scheduling workflows. GCP offer serverless alternatives for both scheduling and workflows: Cloud scheduler and Cloud workflows .
Cloud scheduler is basically a crontab, able to call http endpoints, while cloud workflows can call multiple endpoints while doing parameters and state.
There is one caveat using all of these components. Some of them comes with limitation on how long they are allowed to run before they are killed by the overlords of GCP. Think positive on it. It will force you to write scalable code. There is a kind of beauty backfilling billions of data points in hours, using fan-out patterns, assuming you dont overload the source system of course 😉
The Architecture
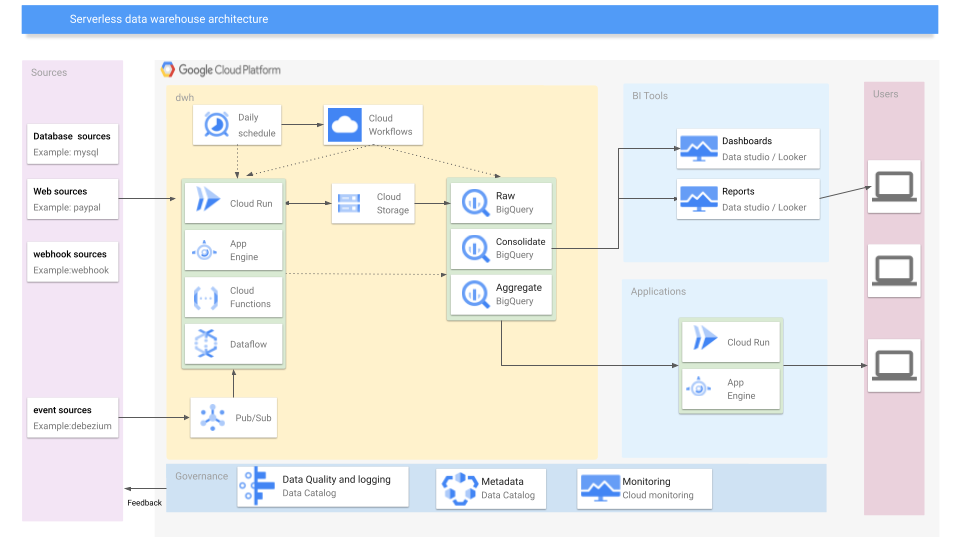
This is an example of how an architecture could look, showing how all the integration components work together.
Data flows from left to right in this architecture. The integration components described earlier fetches data and eventually stores them in BigQuery.
Personally I like to have several layers in BigQuery, where one of the layers is a raw and unmodified layer that is just a copy from the source system, with some metadata added, for example — extract time/load time. The next layer should be a consolidation layer for your raw datasets and you should create a datamodel that answers the business needs.
After the data has been massaged it is time to pull it into a business intelligence tool or a custom app. Data studio is free and web based and is a good place to start. It is lacking, however, especially when you want to deploy dashboards, ownership, etc
With GDPR in mind, its a very good idea to use data catalog to tag your PII (personal identifiable information) data, so you have an overview over where this data exists so you can deal with it appropriately.
Further reading on this topic
The company where I work has just released a whitepaper describing a solution architecture on this, signed by me and my good colleague Per Axel. I suggest you check it out if you found this blog post interesting and want to read more on dwh on google cloud! It has a lot more depth on the datawarehouse layers and business, where this blog post only focuses on the integration layer.
If you need a full enterprise datawarehouse solution for google cloud, I suggest looking at Sharkcell — its a cloud native solution with some unique ideas!
Building a serverless datawarehouse pipeline using GCP was originally published in Grensesnittet on Medium, where people are continuing the conversation by highlighting and responding to this story.