How “Simple Things” Quickly Become Complicated in Software Development
“There’s this little thing that we would like to see automated” — how often haven’t you heard this, knowing that it’s not going to be a little thing at all? Or maybe you’ve said it yourself, even though you know better? Why is it that simple things never stay simple in software development, hindering us to implement the functionality “properly” without the frustration of knowing there are some small things missing here and there, and a couple of shortcuts in other places that you had to make in order to make everything work at least good enough to catch the next deadline for your project?
Together with the other people from Europe Elects, I have a little hobby project collecting key data from opinion polls in a number of European countries. For this project, I need to set up the infrastructure to capture all the information. Doesn’t sound too complicated, does it? Don’t opinion polls look the same in every country anyway? Aren’t they basically a simple list of voting preferences for a number of political parties, with a sample size, a fieldwork period and a polling firm? Well, actually, no, it’s not that simple at all, and a good illustration of how things that may seem very simple on the surface quickly become complicated.
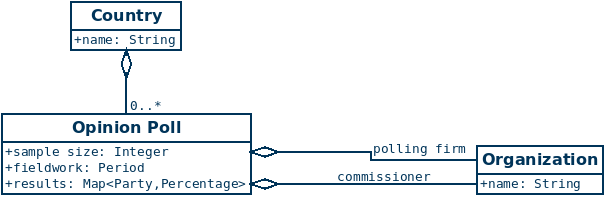
So let’s start in Norway, where it is actually pretty simple. Almost all polls conducted and reported in Norway have a fieldwork period, a sample size and a polling firm, and often, but not always, a commissioner that paid for the people. Or two commissioners that paid for the poll together. Oh, there you go, it already started!
The list of Norwegian parties is currently a fixed set, but you don’t have to go that many years back in the past to find polls that didn’t report on Rødt or MdG. So there’s our second complication: new parties can suddenly appear, without every polling firm starting to report on them immediately. Or small, existing parties suddenly become popular enough so they start to be included in some of the polls.
To make things even more complicated: in Germany, CDU and CSU are often reported together as Union. In the UK, the Scottish SNP and the Welsh Plaid Cymru (PC) are sometimes reported together as Nationalists. In Poland, polls are currently reporting in terms of the electoral alliances of the 2019 general election, and not always the political parties. But at some point in time, there will be a regrouping of parties. All of this has to be handled one way or the other.
Poll results in Norway are usually presented with one digit behind the decimal point. In the UK, it’s usually an integer, whereas in Germany and Austria, you can see halves. You have to capture that information too, because 10.0% (in reality the interval [9.95%,10.05%[) is not the same as 10% (the interval [9.5%, 10.5%[) or 10% (the interval [9.75%, 10.25%[). And in the Netherlands, results are often represented in terms of seats, without voting shares, so you have to cater for that too. And no, the Dutch House of Representatives doesn’t have 100 seats, it has 150 seats, so a result of 10 seats represents the interval [6.333%, 7%[ in terms of voting shares.
But even if you’ve established that the precision is 0.1%, 10.0% can mean different things. Have the people who refused to participate in the poll been excluded from the results? How about the people that said they don’t know, or are undecided? In many countries, undecided voters are excluded from the results, but in e.g. Croatia, they’re not. Furthermore, are we talking 10.0% among the whole population, the people with the right to vote, registered voters or likely voters? And yes, likely voters may be undecided at the time the poll was conducted.
Where was the poll conducted? Seems like a trivial question, but “national” polls in the UK usually cover Great Britain only, but some of them do cover the whole UK. In Belgium, polls are conducted either in Flanders, Brussels or the Walloon region, and the results are always presently separately. So even the concept “country” turns out to have a slight complication.
But even a seemingly simple thing as to who conducted the opinion poll is a complicated matter. In Malta, the poll is sometimes conducted by the publishing newspaper. In Germany, INSA sometimes conducts the interviews, while YouGov processes the data and produces the results. In Spain, CIS sometimes publishes the raw data only, upon which researchers or other companies produce a result for different media outlets, with, of course, slightly different results.
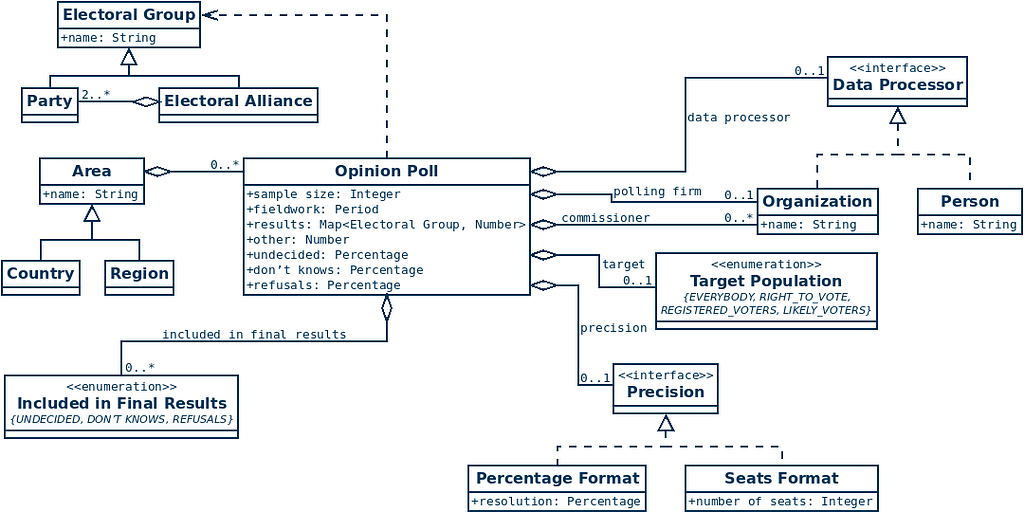
So how difficult is it to store the key data of all the national opinion polls in Europe, preferably in a uniform set of tables? It’s definitely not as easy as it may have seemed like at first glance, and there are still more complications to talk about if you want the full story. Political parties shifting names, for example, or merging together, or hypothetical scenarios. And to be honest, I’m pretty sure I haven’t understood the full complexity of European opinion polls either, let alone what’s out there in the rest of the world.
But this example clearly illustrates how simple things can turn out to be rather complicated, and why it’s so difficult in software development to get everything right from the first time. Humans are extremely good at abstracting away the little details and thus the full complexity of a problem when they look at the big picture. That’s also why we tend to underestimate the complexity of a problem, and hence also the time we need in our software projects. A computer, on the other hand, needs to know every little detail it needs to handle. It doesn’t know when a set of numbers is supposed to add up to one hundred percent, or due to the rounding errors close to one hundred percent, and what that “close to one hundred percent” really means, unless we explain it –specify and implement it– in every little detail.
I’m also sure I’m not the only software developer that has had this feeling from time to time: what if we would just take all the time we need to model the problem in its full complexity, without taking any shortcuts, so that we could be done with it? Wouldn’t that be great? I’m afraid that isn’t really possible, and there will always be annoying shortcuts somewhere in our software domain models. The important thing is to know how many of those shortcuts are acceptable for the problem you’re trying to solve. Very often, that’s just a matter of having enough experience to know when good enough is good enough.
How “Simple Things” Quickly Become Complicated in Software Development was originally published in Grensesnittet on Medium, where people are continuing the conversation by highlighting and responding to this story.