It will all be swept away
How will large language models (LLMs) impact information architecture? Interfaces, data stores, data transformers, pipelines, schedulers, data formats? It will all be swept away and rewritten. Well, much of it anyway.
Let me illustrate with an example from the old days.
In the old days, before computers

Before the advent of information systems, if you wanted to know something, let’s say the company file on a property they own, you needed to speak to someone at corporate records. Let’s call him Smith.
You: “Smith, I need the file on Sodor street. You know, our property there. In the Commodore project, they’re referring to a tenant named Alderson. I need to know the particulars.”
Smith: “Here it is. I’ll send it over. Alderson was a tenant in the early seventies it seems. We have a file on them, I’m sending over a copied page with highlights. And after the war, our holdings at Sodor street were part of the old company back then. It so happens that Alderson owned a small share of that company, and they used the office on the 3rd floor. The one with the lift. I send you a copy of the relevant pages there as well.”
Then we built all this IT information infrastructure
Years later, with the advent of the database it was different. You logged in. You queried the property record table yourself. Then you joined the query with the client record table. After a bit of struggling with the cranky user interface, you had your report for the Commodore project. But perhaps you missed the ancient bits about the client having used the office on the third floor after the war. Maybe it wasn’t digitized information. Or maybe it was in a table you didn’t know about and which the intranet search engine hadn’t picked up.
It will all be swept away. Well, a large chunk at least
I’m using this example to illustrate that man has had to adapt to machines to be efficient at information work. Not the other way around. It is worth contemplating, now that we have these new generative, large language model based (LLMs) artificial intelligences (AIs). Because, in a sense, we are about to have a veritable army of Smiths. Let’s call them “AI Smith”s. Well educated. Excellent memory. Polite. Quick on the uptake. Efficient. Never tiring.
If we had all these Smiths before we started with information systems, would we have built these systems the same way? I think not. I think that we built them with the cranky, brittle interfaces and schemas because it was the best we had and they were better than a single, fallible human. If we had Smiths in abundance, we perhaps would never have built any of the IT infrastructure at all, we just would’ve kept asking Smith for information.
Away with the user interface
We made the user interface, the screen, the responsive design, the accessibility features, the compulsory fields to be filled out, the validation before you could press “submit”, all of it, because Smith was not there to talk to. Now Smith is about to be. And if not all, then quite much of existing user interfaces will be swept away and built anew. The machine will be made to suit man, and not the other way around. Of course, some problem domains are visual in nature, and the visual surface will not disappear, but so much form filling and brittle validation are there because there was no better alternative, and I’m guessing it will be replaced with natural language and dialogue.
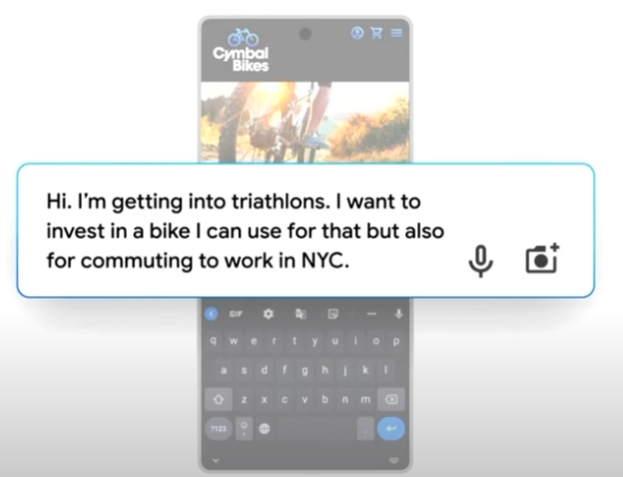
From an example of early work in this direction I see a natural extension from crude shopping assistance chatbots to a dialogue that has the style of an old friend you’re hanging out with, but where advertisements, online sales, advice, multimedia and shipping are all intertwined in a fluid dialogue. I’m not saying that all interfaces will be like this, but you can see in this example, how the old shopping cart is replaced with something that resembles how you would navigate the matter over a dinner table, or with colleagues in a meeting room. Gone is the shopping cart and the item catalogue. It is Apple’s Siri, but where all artificiality is gone and hadn’t it been for the demi godlike abilities it has of knowing everything, representing a million agencies and being a global logistics operator, it could’ve been that old friend you’re speaking to. Whether this is dystopian or utopian, it is at least what user experience professionals (and data privacy specialists) increasingly will be dealing with. I wager a good chunk of all canvas based, forms based and select and submit like interfaces will be swept away.
Away with the database
If we had “AI Smith”, remembering all the records and, as old human Smith did, associating accurately across records and history, why would we need the SQL database? The database is not a perfect solution for answering human queries. It was just the best we had.
My take is that over some years, all of those databases where the need ultimately comes from human queries, will be scrapped or rewritten. Perhaps not all. And very gradually over a generation perhaps. But still, quite a lot of them. And they are many.
We see glimpses of how this will happen. How natural language may and will replace query languages. Surely, for some challenges, the precision that the query language gives you will trump other needs, but for many human-centric needs, as the example with Smith at records show, the semantics and back and forth dialogue that humans excel at, will be more important.
And on a deeper level, maybe the database itself, not just the interface will change. Combining your own data with an LLM is a hot topic that vendors and open source communities are racing to address. Present approaches, both via so-called fine tuning and through few-shot learning, have significant disadvantages. How to store and learn from a steady stream of new information is an open research area. The ways large language models will impact data management are clearly unknown but some argue it will be disruptive, where key industry challenges will be revisited for new solutions and patterns.
Away with json, xml, mof, bpm, edi, rest etc
And if you’ve replaced your database with “AI Smith”, what about the interfaces, the APIs, internal to the application you used in the office to query the records? In many cases there are of course legitimate needs for precise, brittle, defined, formal communication protocols. Particularly when the original source is a sensor for example, or when the end-user is a machine. The protocols are painful nevertheless. They break down. Semantics are lost for every transform. New needs arise and the work to formalize and incorporate new expressions and new meanings take enormous effort.
If at one end you have an information producer that originally was human and the content is language based, and at the other end you have a human consumer, then perhaps all those defined, brittle protocols in the middle of information architectures are more pain than gain?
Here as well, my take is that over some years, a good chunk of all interfaces and communication protocols will be scrapped and rewritten as well. I don’t know exactly how many at the end, and not how fast. But there will be an enormity.
Research gives us some indication on how component communication and interfaces may look in the future. Firstly, you got the obvious, the communication between machine and a human, which now, thanks to LLMs may increasingly be happening in a language suitable for man. Then, you’ve got communication between LLM empowered machine components, where for example, new more efficient negotiating strategies may be pursued. Here the language is still human language. But it clearly doesn’t need to be. If the human is out of the loop, but a deep neural network is talking to another, altogether new, efficient communication forms may emerge with alien semantics and syntax, but that functionally is a better fit.
This concludes my speculation. There are exciting times ahead. And if I’m right, no shortage of refactoring work for developers (like us at Computas) and probably for Smith as well. AI Smith that is!
It will all be swept away was originally published in Compendium on Medium, where people are continuing the conversation by highlighting and responding to this story.