What is Data Mesh?
Introduction
The term ‘Data Mesh’ has become increasingly common over the past few years, though it is still somewhat niche compared to terms like Data Lake or Data Platform, and what it actually means might not be well understood. In this article I will delve into what data mesh actually is, the motivations behind it, and how you can start implementing it into your organization.
Background
During the past decade, particularly with the advent of cloud computing, many IT projects, especially in the BI/Analytics space, have struggled to realize the benefits or solutions that they set out to achieve. The projects might have taken longer or been more difficult than initially envisioned, the solutions might not have attained the required quality (particularly data quality), and existing problems around data trust and governance might still cause problems (and in some cases have become exacerbated by a move to the cloud). At the same time, becoming data-driven is among the top strategic goals for organizations today; making better decisions, providing better and more customized customer-services, reducing operational costs and giving employees powerful insights into their business is key to success, and CEOs know this is what their competitors are trying to achieve.
One of the primary reasons for the challenges faced by the projects mentioned above is that to a large extent they have been primarily technical exercises. A focus on product, platform and feature choice have overshadowed areas such as people, processes and culture. This does not suggest that these solutions must fail, or that the technical issues are unimportant , but it highlights one of the major rationales for data mesh.
Another issue is that while there has been significant advances in software engineering during the past couple of decades around things like product-thinking, micro-services and robustness, the same has not happened (at least to the same extent) in the data warehousing and business intelligence space. This has been compounded by a “knowledge-gap” between IT and the Business users; IT typically has very strong technical skills, but often have less insight into which data Business Users use, how they use it and when, at least often less insight than they think they have. At the same time, Business Users often do not know the underlying data, it’s sources and quality as well as they think they do. There is also frequently a divide between operational and analytical data both technically and organizationally.
Furthermore, the variety and volume of data sources that organizations have to manage and the increased need for organizations to innovate, adapt to change, and meet (new) customers in different ways have added to the challenges faced by these projects.
Rationale
Imagine going to your favorite web-shop, for example for ordering food, and having to contact the individual producers of food for access, having to spend a lot of time figuring out what the products are or how they were produced. This wouldn’t work. But for getting access to and consuming data today this is to varying degrees what goes on every day in many small and large organizations. These sorts of problems are one of the main things data mesh seeks to resolve.
So what is data mesh?
Data mesh is a set of practices and paradigms with an overall goal of allowing data consumers to focus on consuming data, rather than interpreting or understanding their characteristics. It is a new way of looking at data in an organization; from governance and quality to lifecycle. Data Mesh is NOT technology or a product. And it is still evolving and being developed. There is no real reference architecture at the moment, and implementing it is nontrivial and time-consuming.
While traditionally the focus has been on extracting value from the data, in the data mesh paradigm the data is the value. Rather than looking at data from a technical perspective, we see data as the organization’s products and resources. Data Mesh revolves around people, processes, business culture and organization. While technologies and products are required to implement a data mesh, in itself it is not technology. This is in stark contrast to for example Data Lake or Data Platform which is (primarily) technology or product.
In the data mesh paradigm, domains host and serve their data products for easy consumption, rather than data flowing through an ETL-type process to some centralized data warehouse.
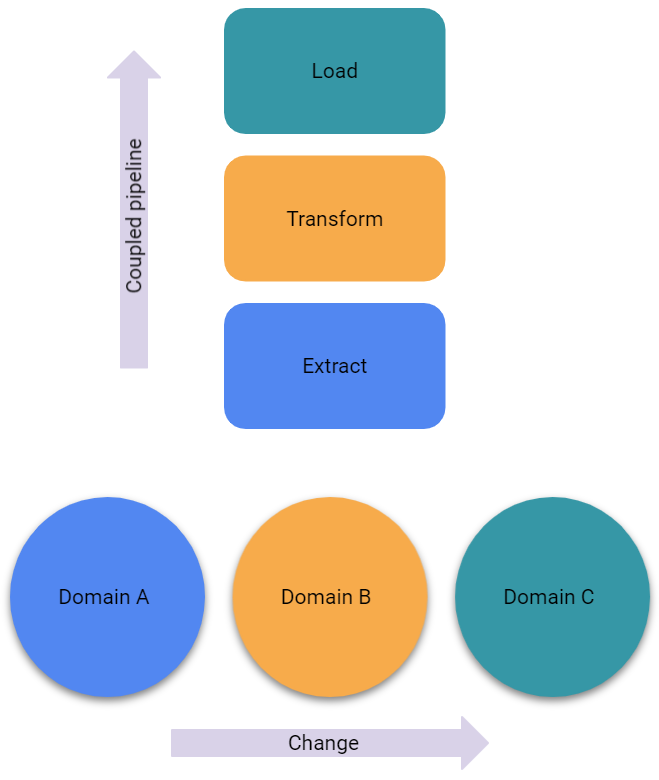
The last point is worth examining a bit closer. Operational systems or domains represent business functions either solely, or in collaboration. These systems change or develop over time. At the same time, the pipelines implemented in the ETL (or ELT) value chain are strongly coupled steps that support analytical business needs. So when the operational systems change to support new or modified business processes, these changes propagate from the point of change to the point of consumption, because these coupled pipelines are orthogonal to the axis of change (and time). So changes need to be made throughout all steps of the processes/pipelines involved. Some automation can certainly be implemented, but this is one of the (main) reasons why traditional solutions have a tendency to become inflexible and time consuming to maintain in the face of an increasing pace of change in business, varieties in data types (semi-structured and unstructured) and new customer requirements.
Vision
One of the core tenets in the data mesh paradigm is a division between producers and consumers of data; buyers and sellers of data products. The idea is that sellers of data products will be more engaged, more invested, in the quality and consumption of their products.
Data consumers are at the center of the organization, they are the customers; and consuming (new) data should not be a technical issue. Data must be self-describing and documented, and customers should be able to consume all the data in the organization as an “as-a-service Solution”. Consumers should not have to interact with sellers of data (products), since they would become bottlenecks.
Another vision is that the owners of the operational data are not only responsible for providing the business capabilities represented by their domain, but also the facts of their business domains as consumable data products. This is a lofty goal since it can be challenging to properly map the operational business domains to desired statistical or analytical business facts, not merely technically but also organizationally. Different business units have different vocabularies, definitions and needs.
Data Mesh also advocates having a unified, company-wide strategy, rather than various units where some focus on technical aspects while others focus on the business side.
From theory to practice
So what does this mean in practice?
For one thing, it means that consumers of data must be independent of the production and change of data. There must be trust in the data products; all QA should happen on the side of the producers/sellers. Typically, today, this is not the case in many data warehouse solutions; responsibility for this is (unintentionally) delegated to downstream systems or consumers.
Secondly, since data mesh is not technology or product in itself, it means people, organization and culture need to be at the center. And changing these things takes time. This means that the sponsoring and anchoring needs to be at a very high level in an organization; it is not just an IT-project, with the understanding that change will be gradual and sometimes difficult.
Organizations should also consider their size and how much effort it will actually take to fully embrace a data mesh paradigm, it is quite possible that some minimum-size is recommended or required to justify this investment in time. Especially considering that data mesh is still not mainstream and is still being developed and refined.
But a lot of the rationale behind data mesh and the vision it has can be used regardless of fully committing to a data mesh strategy.
Thinking data products
As mentioned under “Background”, product-thinking has developed significantly in the software engineering discipline. So what does product-thinking mean in the data warehouse/analytics space? How do you approach this area?
First of all, you must involve the right people in this process; key people are business process owners and domain experts. These people must sit down with IT and solution architects to discover and identify which areas and processes your business consists of, how to partition them and assign ownerships.
Secondly, you must get control over master data and data quality so that you can produce consumption-ready data products where data-quality is not delegated to consumers or downstream systems. Typically, in the data mesh paradigm domain data teams must provide data sets that are discoverable, addressable, trustworthy (according to service-level agreements and continuously monitored), self-describing, interoperable and secure.
Discoverable data means available through some data catalogue. Addressable relates to standardized naming conventions and formats. Trust is about getting control of your data quality. Self-describing means that the consumer is not dependent on the producer in order to use and understand the data product. Interoperable allows data products (from different domains) to be used and correlated easily, requiring harmonization and standardization. And finally, secure means in accordance with security requirements and GDPR compliance using single sign-on and role-based access control, often catering to both internal and external consumers.
Finally, you must realize that these are ongoing processes; data quality, data governance, master data management and data-product development is not a one-time issue, rather they are continuous tasks.
First Steps
The following first steps is a good place to keep in mind if you want to start moving towards data mesh or if your organization just wants to try to get the best benefits from the practices;
- Get expert help. Use people with experience in this area to gage the size and readiness of your organization to embark on a data mesh journey.
- Identify one business area to start with. This should be a business area or function with high importance for the business and low technical complexity. Finding the right balance here can be challenging.
- Reduce the number of technologies involved
- Infrastructure should/must be “as-a-Service”
- Start small
- Begin developing templates for how to produce data-products
- Implement versioning of data sets (particularly important around source-oriented domain master-data like like codes and vocabularies)
- Start measuring data quality immediately; you can’t act to resolve issues if you are not aware of them.
Conclusion
Data Mesh is still somewhat in its infancy. There is no reference architecture one can look to, but the underlying ideas, motivations and goals are well understood. Technology is available to start moving towards data mesh solutions, but the challenges will typically relate to cultural, organizational and cost (time) issues.
Success will require some fundamental shifts in skillsets, principles and the way we think about these solutions. Instead of thinking about a centralized data platform or data lake we will think about an ecosystem of data products. Instead of ETL we will think of discovery and use. Instead of extracting data from sources we will think about serving domain data products.
What is Data Mesh? was originally published in Grensesnittet on Medium, where people are continuing the conversation by highlighting and responding to this story.